We have reached the end of the digitization process
Or better… the most important… most advanced part is missing.
In fact, we have reached the top of what we mean today when we talk about the digitization process.
In this last episode we will talk about something as crucial as it is urgent: a Data Acquisition system.
Why urgent?
Because those who succeed or those who have already acquired a lot of data related to their processes, are already setting the foundations for a huge future competitive advantage as well as having the most powerful tools available to improve their performance right away.
But, as always, let’s first do a quick recap of the previous episodes.
Summary of previous episodes
We started with a simple machine, without any “smart” element and, slowly, we added “intelligence” to the machine and noted all the valuable information we could acquire.
Initially we simply “took a picture” of our production efficiency, thanks to the addition of PLCs, HMI stations and various sensors: through modules such as OEE and Andon we got to know where the waste was hiding (machine stops, flow speed and waste). Starting from this knowledge we went to improve, our performances step by step: the Machine Ledger was useful to limit the machine stops; we helped the operators to speed up their work and to limit their mistakes with the Visual SOP; we worked on the quality of the products with solutions like Pick to light and Vibco; finally, we intervened again on the speed, but also on the quality of the products, with the solutions dedicated to logistics, such as the digital Kanban and the Warehouse Management System.
Data acquisition: Why?
When we talk about data acquisition, we are saying that we want to store a lot of information, the so-called big data, which we have heard so much about since the industry 4.0 era began a few years ago.
In a short period of time, huge step-ups have been made. What they said could have been done, today can be done and quite easily if you have the most up-to-date software technologies.
The data, in fact, has always been important, and, in some way, everyone has always tried to “learn more” about how they were performing and how much they could save.
So, what’s changed from yesterday?
Two crucial aspects:
1. The acquisition process can be automated to the maximum, thus being able to easily generate large masses of data in matrix form that can continuously self-increase
2. In addition to acquiring raw data, we are now able to collect them in organized datasets and combine data coming directly from the field, with other data coming from combinations of other variables or mathematical models.
The advantages of a system of data acquisition
The data we’re talking about is nothing more than very detailed information. This deep knowledge of the status of things as well as this very sharp “picture” of how we are performing, is useful for us to take advantage in two ways:
- Monitor and control runtime variable values and automatically trigger (in case of an OOC) “actions” related to those values (feedback to the process, sending emails, scheduling maintenance events in Machine ledger 4.0, telegram messages, etc.).
- Analyze a large amount of data, “train” deep learning models, with the aim of implementing predictive actions to avoid or predict future OOC.
The data source
The first thing to do when we decide to equip ourselves with a data acquisition system is to identify the sources of our data. These can be of different types: generally, PLCs, but for example also energy meters can be a source. Ultimately, we could say that any IoT field device can be a source to acquire data directly and automatically from the field.
Other sources can be the manual insertion of values by the operators; other data can come from the transformation of other acquired datasets, through the combination with other variables.
The PLC
We said that the goal is to have organized datasets. These datasets can be associated to the resources that are managed by the system (machines, production lines, etc..): through the configuration of our datasets, we will then be called to define the structure of the resources, until we identify the production line and, finally, the field IoT devices, such as a PLC.
We made the example of the PLC, because we already talked about it in the previous episodes.
The PLC can adopt various protocols such as, Snap7, Modbus TCP, OPCUA: this is not a problem.
The PLC then will be our data source: through a very simple interface it is possible to represent the PLC and the associated datasets and, finally, it will be possible to configure the field variables we need, the sampling frequency, the address of the PLC memory areas and other useful parameters.
This is our source: extracting data from the PLC is the job assigned to IMPROVE’s Software Agents…
Let’s see what it’s all about.
IMPROVE 4.0
Agents on a mission
IMPROVE 4.0 is the NeXT framework realized by using a very innovative programming paradigm: the Agent paradigm, particularly suitable for developing Artificial Intelligence algorithms.
In very few words, we can say that an Agent is a software that “lives” to pursue a specific mission.
In this Data Acquisition system, the involved agents are various.
The first Agent has the mission of retrieving, with a certain frequency, the values of the variables that reside in precise memory areas of the PLC. These values are then made available in the memory of the IMPROVE system.
This information will then be delivered to another Agent that has the mission to “photograph” the current value of the variables: this agent in fact constitutes the real memory of all information flowing from the field.
In conclusion, this agent will be “questioned” by a third type of agent, which will put the values of the variables in relation to those that were previously set during the configuration phase.
Variables Configuration
Let’s take a step back, to when we configured the variables of the process we are interested in acquiring and monitoring.
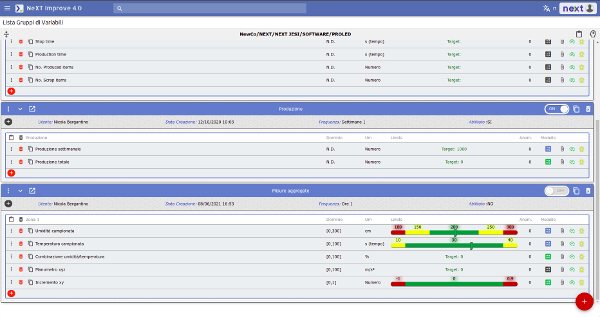
Variables Configuration
A description of the variable is provided, a domain defined, measurement units, reference values or tolerance thresholds. At the time of the acquisition, the third-party agent will compare the values in his possession with those already set, all of this in order to determine the existence of an “out of control”.
The concept of “out of control” is absolutely relevant.
It is the basis of the automation of the Digital Acquisition solution..
An out-of-control event immediately becomes a trigger for a series of possible actions/events:
- Feedback straight to the process
- Sending of e-mails
- The automatic scheduling of a CBM maintenance intervention
- Sending a message on Telegram
- Whatever you need
The value of the configured variables can be of different types. For example, it can be represented by a limit, beyond which there is an OOC (Out of Control); it can consist in a threshold or interval. When this happens zones will be identified, represented by a different coloring: the red one represents the OOC area while the green and yellow areas represent acceptable values.
Other values will be the result of the connection with other datasets acquired through the specification of an aggregation criteria, or combinations with other variables through mathematical models.
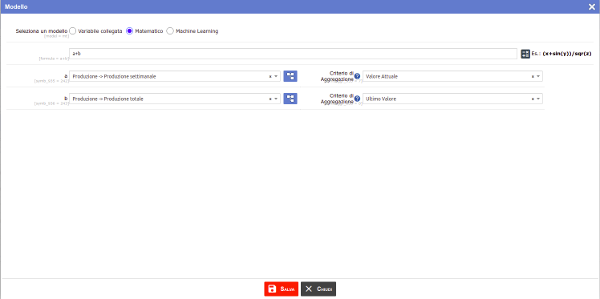
Models
In conclusion, it is possible to import deep learning models and then be able to perform functions that would be too complex for a simple mathematical model.
Data analysis
Once all the data’s been acquired it is necessary to pass to the phase of data analysis.
For this reason, the data are structured and organized, both in tabular and graphical forms.
The used techniques for the analysis phase come straight from the statistical process control:
- Trend analysis of the variable
- Statistical analysis
- Process capability analysis (cp, cpk)
- Histogram (form of distribution)
- Gaussian analysis
- Pareto diagram
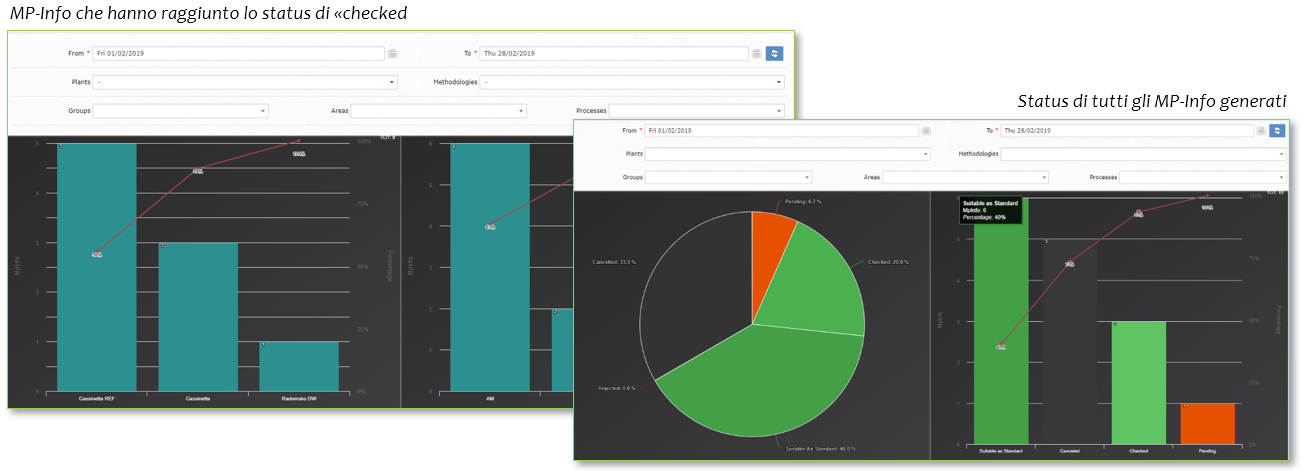
Data analysis & reports
TOOLBOX:
– A IoT device
– Data acquisition Module
If you’re interested in the themes that we’re covering, follow and text us on Linkedin: we’d like to know YOUR opinion
You may want to use something even quicker, in that case, follow us on Telegram!



