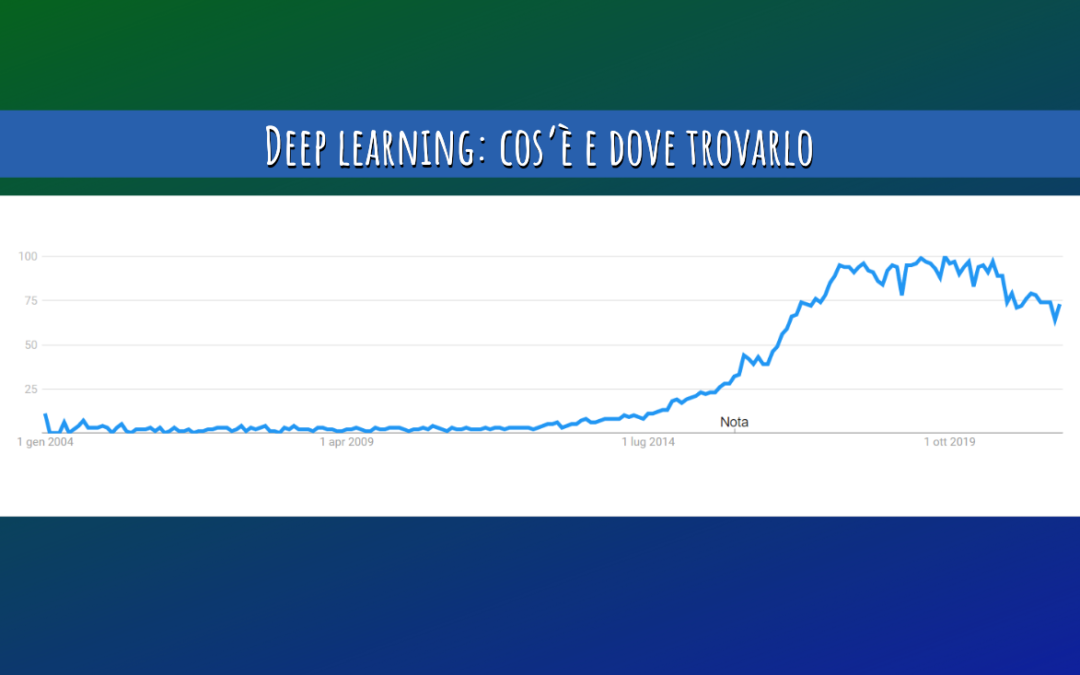
È indicativo il grafico dei trend di ricerca in Google dei termini “deep learning”, negli ultimi 17 anni.
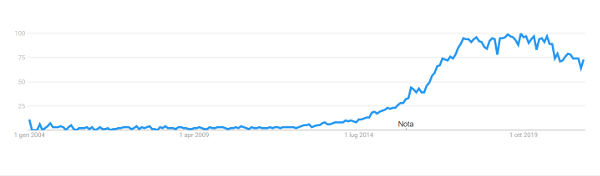
Deep learning nelle tendenze di ricerca
C’è un motivo che spiega questo innalzarsi dell’interesse per questo argomento, ma prima di soffermarci su questo, cerchiamo di spiegare cos’è precisamente il deep learning.
Cos’è il deep learning
Spesso vengono utilizzati in maniera impropria, quasi come fossero intercambiabili, i termini deep learning, machine learning e intelligenza artificiale.
Si tratta in realtà di concetti completamente differenti, ma legati, in qualche maniera, tra loro.
Il deep learning è uno dei metodi dell’apprendimento automatico, cioè del machine learning, attraverso il quale è possibile creare quella che viene chiamata Intelligenza Artificiale.
Quest’ultima può essere definita come qualsiasi tecnica che consente ai computer di imitare l’intelligenza umana, utilizzando la logica, le regole if-then, gli alberi decisionali e l’apprendimento automatico (o machine learning).
Quindi, l’Intelligenza Artificiale costituisce l’obiettivo finale, il machine learning la strada per raggiungere questo obiettivo. Questa strada prevede la capacità delle macchine di acquisire dei dati (molti) e di imparare automaticamente da essi, attraverso l’addestramento di modelli che consentono di modificare e adattare gli algoritmi in accordo con le informazioni disponibili.
Il Machine learning include tecniche statistiche astratte che consentono alle macchine di migliorare le attività attraverso l’esperienza. Esistono diversi approcci per attuare l’apprendimento automatico: uno di questi è il deep learning.
Il deep learning è quindi una sorta di sottoinsieme dell’apprendimento automatico composto da algoritmi che consentono al software di addestrarsi a svolgere compiti (es. il riconoscimento del parlato o di immagini) esponendo reti neurali multistrato a una grande quantità di dati.
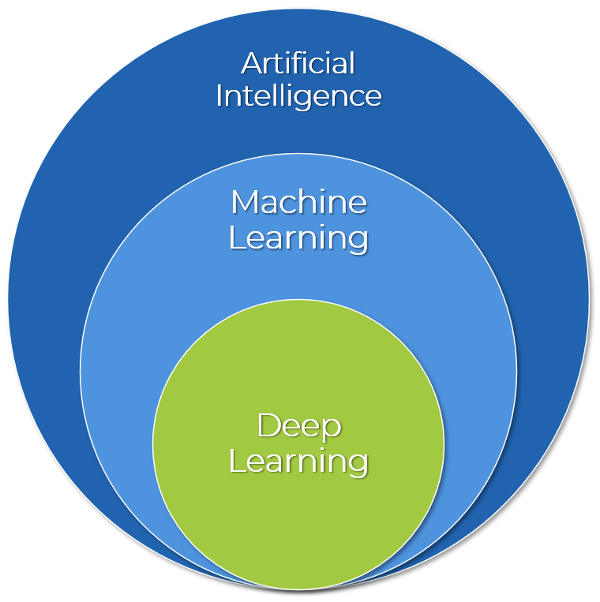
Differenza tra Intelligenza Artificiale, Machine Learning e Deep Learning
[Per fare l’esempio di un altro approccio, possiamo citare le reti bayesiane, che in passato NeXT ha utilizzato per un algoritmo di Intelligenza Artificiale per la soluzione di problemi di qualità durante il processo produttivo.]
Il Deep Learning sfrutta architetture e modelli matematici che prendono il nome di reti neurali multistrato. Queste reti prevedono una grande quantità (parliamo di decine a milioni) di livelli (o strati) di neuroni artificiali coinvolti: da qui l’utilizzo del termine “deep”. L’obiettivo di questo sistema di neuroni è quello di cercare di replicare il funzionamento del cervello umano.
Deep learning: le tecnologie abilitanti
Se il Deep learning fosse una pietanza potremmo cercare di fornire la ricetta per realizzarlo al meglio.
Proviamo a fare proprio questo, cercando anche di capire come mai proprio ora il deep learning stia esplodendo, sia nell’interesse generale, come si evince dall’immagine presente ad inizio articolo, sia nell’interesse del mondo del lavoro, testimoniato dalla moltiplicazione dei corsi universitari dedicati (di ingegneria, ma anche di materie economiche, sociali e umanistiche), che sono nati negli ultimi tempi.
Primo ingrediente: Big data
Da diversi anni, a partire da quella che tutti chiamiamo Industria 4.0, cioè la quarta rivoluzione industriale, abbiamo sentito parlare di Big data. Potremmo dire che si tratta effettivamente della rivoluzione dei dati. I dati hanno un’importanza centrale oggi, anche grazie ad un altro elemento abilitante come l’Internet of Things che ha contribuito in maniera determinante a creare un ecosistema connesso e digitale, sia nel contesto quotidiano della nostra vita, sia nel contesto industriale degli stabilimenti.
È sempre più facile reperire i dati e farli fluire: la mole dei dati è un elemento cruciale, anzi necessario, per poter sfruttare con successo un modello di deep learning.
Quindi primo step: dotarsi di un sistema efficace e performante di data acquisition.
Secondo ingrediente: algoritmi di apprendimento automatico
Gli algoritmi di apprendimento automatico servono ad addestrare i modelli utilizzando la grande mole di dati di cui abbiamo parlato nel precedente paragrafo.
La differenza sostanziale tra il deep learning ed un algoritmo tradizionale sta nel fatto che il comportamento di quest’ultimo è stabilito dal programmatore, il quale fornisce anche i dati (quantitativamente limitati) da utilizzare: in un modello di deep learning, invece, l’algoritmo apprende (si addestra) proprio dai dati (in grande quantità) che tipo di comportamento seguire.
Questi algoritmi possono essere scritti attraverso i linguaggi di programmazione tradizionali (C++, Python, Java e Javascript, ecc.): la teoria e gli algoritmi esistono già trent’anni, ma solo dopo il 2012 il deep learning è effettivamente decollato grazie a piccoli ma determinanti miglioramenti nell’algoritmo che consentirono l’utilizzo di reti neurali multistrato (le reti neurali, in precedenza, erano ancora piuttosto superficiali, con solamente uno o due layer di rappresentazione).
Altri miglioramenti avvenuti tra il 2014 e il 2016, consentono ora di eseguire l’addestramento a partire da modelli di base che hanno una profondità di migliaia di layer.
Perché ciò avvenga però, è necessario il terzo ingrediente.
Terzo ingrediente: la potenza di calcolo
La riuscita di una buona pizza dipende dalla temperatura a cui si riesce a cuocere. Per questo difficilmente a casa riusciremmo a fare una pizza come in pizzeria: il forno elettrico arriva massimo a 250 °C, mentre il forno a legna arriva fino a 400 °C.
Così, per poter utilizzare modelli di Deep learning deve essere possibile utilizzare molta potenza di calcolo e memoria (storage).
Questo elemento, in passato, è stato un elemento frenante per lo sviluppo dell’Intelligenza artificiale. Oggi la potenza dei computer consente di utilizzare modelli di deep learning, tant’è che noi, forse non sempre consapevolmente, utilizziamo l’intelligenza artificiale, quotidianamente.
Facciamo un esempio concreto. In ambito natural language processing si sono fatti passi da gigante, ma gli algoritmi sono più o meno gli stessi: c’è stato piuttosto un grande avanzamento della tecnologia nel mondo dell’hardware e della capacità di archiviare dati in cloud.
Il fattore cruciale è stata la possibilità di utilizzare i processori grafici (GPU) in parallelo alla CPU. Questo ha consentito di eseguire operazioni di calcolo intensive.
È chiaro che i risultati più ambiziosi si avranno quando, ad esempio, verranno realizzati computer ancora più potenti, come ad esempio i cosiddetti computer quantistici.
Ad oggi, la capacità di una rete neurale di deep learning è limitata ad un obiettivo molto specifico: se deve riconoscere un volto umano, non potrà essere utilizzato per riconoscere il volto di un’altra specie.
In pratica, ogni neurone artificiale risponde ai dati di input (sinapsi) con uno “0” o un “1”. In base a questo valore ricevuto dal neurone precedente, la sinapsi invia o trattiene un segnale ai neuroni dello strato successivo, i quali elaborano i dati che hanno ricevuto e trasferiscono l’output alle cellule del livello successivo.
La ricerca sta andando nella direzione di imitare il più possibile il funzionamento di un neurone umano, il quale è qualcosa di più complesso del neurone di una rete di deep learning: non è un’entità singola, ma ciascun neurone è costituito da un complesso sistema di ramificazioni, con molteplici sotto regioni. Le conseguenze sono interessantissime, perché a così il neurone potrebbe essere considerato a sua volta come una sotto rete, con tutte le implicazioni che questo comporta.
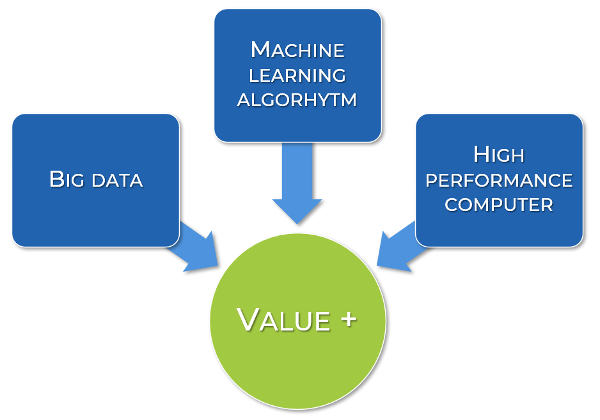
Il funnel del valore
L’Intelligenza Artificiale: sue applicazioni nella vita di tutti i giorni
Forse non ce ne rendiamo conto, ma utilizziamo l’intelligenza artificiale tutti i giorni.
Quando ci facciamo guidare dal navigatore nei nostri viaggi, quando facciamo una ricerca su Google, quando facciamo acquisti online o interagiamo con un assistente vocale intelligente, stiamo utilizzando intelligenza artificiale.
Volendo elencare alcuni settori dove il deep learning viene utilizzato oggi, possiamo citare ad esempio:
- Natural language processing (NLP)
si riferisce al trattamento informatico del linguaggio naturale. Questo viene distinto dal linguaggio formale, del quale fa parte anche il linguaggio del computer. L’interesse verso questo tema è cresciuto esponenzialmente negli ultimi anni trascinato dall’esplosione dei device mobile. La complessità del lavoro nel campo del linguaggio natuale, sta nel fatto che rispetto al linguaggio formale, questo è molto più complesso, contiene sottointesi e ambiguità, il che lo rende molto difficile da elaborare.
- Computer vision
Fa parte di questo campo l’emergente guida autonoma e dell’elaborazione delle decisioni e delle azioni giuste da intraprendere in tempo reale
- Robotica
Il deep learning sta consentendo la creazione di robot sempre più autonomi e attrezzati con sistemi di NLP e computer vision per il riconoscimento delle immagini, l’elaborazione sensoriale tattile e olfattiva
- Recruiting
Oggi l’intelligenza artificiale viene utilizzata per selezionare il miglior candidato da assumere: l’intelligenza artificiale può scegliere velocemente tra centinaia di CV, basandosi su molteplici parametri ritenuti importanti
- Suggerimenti d’acquisto
L’Intelligenza artificiale può imparare a conoscere ciascun internauta in maniera sempre più dettagliata arrivando a capire e persino a predire i propri gusti e i propri desideri d’acquisto.
- La diagnostica medica
Il Deep learning va a potenziare enormemente ciò che fa già ogni singolo medico: prendere decisioni basate sulle proprie conoscenze ed esperienze. Si può operare sia nel campo della diagnostica medica, sia in quello del controllo di qualità nelle produzioni farmaceutiche.
L’utilizzo del deep learning nel mondo industriale
Nel mondo industriale, Big data e Internet of Things sono concetti abbastanza familiari da diversi anni. Questi due temi sono stati sempre elencati tra le tecnologie abilitanti per l’Industria 4.0.
Il processo di digitalizzazione che moltissime aziende in questo settore hanno da tempo intrapreso, sta creando un ecosistema ideale e pronto per lo sfruttamento di modelli di deep learning.
L’Intelligenza artificiale si sposa in maniera assolutamente sinergica con il concetto di Internet of Things, tant’è che non è errato pensare a questi due temi allo stesso modo con cui accostiamo il cervello (l’AI) e il corpo (IoT).
Nell’era “Industria 4.0” il concetto di Internet of Things è diventato parte integrante di qualsiasi processo produttivo e non. Siamo circondati da device “intelligenti” in grado di comunicare tra loro, nello stabilimento e tra stabilimenti, in un environment iperconnesso: PLC, sensori, server, device wearable.
I dati viaggiano veloci, ovunque.
Gli utilizzi dove il deep learning porta un maggiore valore aggiunto vedono l’implementazione di modelli per la manutenzione predittiva; per migliorare enormemente l’efficienza del processo produttivo, guidando il processo decisionale dei manager.
Andiamo nel dettaglio.
- La manutenzione predittiva
Il tema delle manutenzioni è un tema molto caldo. La loro progressiva digitalizzazione consente l’utilizzo di strumenti sempre più evoluti che hanno l’obiettivo di gestire tutti i tipi di interventi e di eliminare completamente quelli di tipo reattivo (cioè il guasto “improvviso”).
Come è possibile fare questo? Utilizzando modelli di deep learning all’interno di sistemi software avanzati (es. un Machine Ledger). Questi modelli sono in grado di monitorare migliaia di variabili, e di schedulare in maniera automatica un evento di manutenzione nel preciso istante in cui emerga un valore di variabile “fuori controllo”.
La conseguenza dell’utilizzo dell’intelligenza artificiale per le manutenzioni è che i componenti di una macchina vengono sfruttati il più possibile, venendo però sostituiti prima che causino un fermo macchina improvviso. Sfruttiamo quindi l’intero ciclo di vita di ogni componente, andando anche a limitare la quantità di scarti prodotta ogni anno. Un impatto ambientale quindi positivo.
In questa maniera vengono superati i concetti di manutenzione preventiva o proattiva, a favore di una manutenzione predittiva.
- Miglioramento dell’efficienza produttiva
In un ecosistema digitalizzato, in cui i dati fluiscono dai device di campo verso i sistemi software che quei dati li devono strutturare e organizzare, la possibilità di implementare dei modelli di deep learning migliora in maniera esponenziale l’efficacia dei semplici modelli matematici, altrimenti utilizzati.
Anche qui vengono monitorate migliaia di variabili: ogni “fuori controllo” di qualsiasi natura, diventa un trigger per una serie di eventi, compresi feedback in tempo reale verso il processo.
Se vi interessano i temi che affrontiamo, iscrivetevi alla nostra Newsletter, per rimanere sempre aggiornati sui contenuti che pubblichiamo.
Ci piacerebbe conoscere il vostro parere. Seguiteci su Linkedin!
Ma se volete seguirci nella maniera più veloce e agile, seguite il nostro canale su Telegram!
Ascoltando: U2 – “Beautiful day”
Lettura in corso: “Strategia oceano blu: vincere senza competere” di W. Chan Kim e Renée Mauborgne
Mood: Green















Commenti recenti