
Siamo arrivati alla fine del processo di digitalizzazione
O meglio.. manca la parte più importante.. più avanzata.
Siamo giunti infatti al vertice di ciò che oggi intendiamo quando parliamo di processo di digitalizzazione.
Parleremo in questa ultima puntata di qualcosa tanto cruciale quanto urgente: un sistema di Data Acquisition.
Perché urgente?
Perché chi riuscirà o chi ha già acquisito molti dati relativi ai propri processi, sta già ponendo le basi per un enorme vantaggio competitivo futuro; oltre ad avere a disposizione gli strumenti più potenti per migliorare le proprie performance sin da subito.
Ma, come sempre, facciamo prima un veloce recap del puntate precedenti.
Riassunto delle puntate precedenti
Siamo partiti da una macchina semplice, priva di ogni elemento “smart” e, piano piano, abbiamo aggiunto “intelligenza” alla macchina e constatato tutte le preziose informazioni che potevamo acquisire.
Inizialmente abbiamo semplicemente “scattato una fotografia” della nostra efficienza produttiva, grazie all’aggiunta di PLC, postazioni HMI e sensori vari: attraverso moduli come l’OEE e l’Andon siamo andati a conoscere dove si nascondeva lo spreco (fermi macchina, velocità del flusso e scarti). Partendo da questa conoscenza siamo andati a migliorare , punto per punto, le nostre performance: il Machine ledger ci è servito per limitare al massimo i fermi macchina; abbiamo aiutato gli operatori a velocizzare il proprio lavoro ed a imitarne gli errori con il Visual SOP; abbiamo lavorato sulla qualità dei prodotti con soluzioni come il Pick to light e il Vibco; infine, siamo intervenuti ancora sulla velocità, ma anche sulla qualità dei prodotti, con le soluzioni dedicate alla logistica, come il Kanban digitale e il Warehouse Management System.
Data acquisition: perché?
Quando parliamo di data acquisition stiamo dicendo di voler entrare in possesso di molte informazioni, i cosiddetti Big data, di cui abbiamo tanto sentito parlare da quando è iniziata, una manciata di anni fa, l’era Industria 4.0.
In poco tempo si sono fatti passi da gigante. Ciò che si diceva che si sarebbe potuto fare, oggi si può fare e in maniera piuttosto agevole se si è in possesso delle tecnologie software più al passo con i tempi.
I dati, in realtà sono stati sempre importanti, e, in qualche maniera, tutti hanno sempre cercato di “saperne di più” su come si performava e su quanto si potesse risparmiare.
Cos’è cambiato rispetto a ieri?
Due aspetti fondamentali:
1. il processo di acquisizione può essere automatizzato al massimo, potendo quindi generare agevolmente grandi moli di dati in forma matriciale in grado di autoincrementarsi continuamente
2. oltre ad acquisire il dato grezzo, oggi siamo in grado di collezionarli in dataset organizzati e combinare i dati che arrivano direttamente dal campo, con altri dati derivati da combinazioni di altre variabili o da modelli matematici.
I vantaggi di un sistema di data acquisition
I dati di cui parliamo non sono altro che informazioni.. molto dettagliate. Questa conoscenza così profonda dello stato delle cose, questa “foto” così nitida di come stiamo performando, la possiamo sfruttare in due modi:
- Monitorare e controllare runtime i valori delle variabili e innescare automaticamente, in caso si verifichi un OOC (out of control), «azioni» correlate ai questi valori (feedback verso il processo, invio mail, schedulazione eventi di manutenzione nel Machine ledger 4.0, messaggi telegram, ecc..)
- Analizzare una grande mole di dati, «addestrare» modelli di deep learning, con lo scopo di implementare azioni predittive per evitare o predire futuri OOC.
La sorgente dei dati
La prima cosa fare, quando decidiamo di dotarci di un sistema di data acquisition è individuare le sorgenti dei nostri dati. Queste posso essere di diverso tipo: in genere sicuramente dei PLC, però ad esempio anche dei misuratori di energia possono costituire una sorgente. In definitiva, potremmo dire che qualsiasi device di campo di tipo IoT possono costituire delle sorgenti per acquisire dati direttamente e automaticamente dal campo.
Altre sorgenti possono essere l’inserimento manuale di valori da parte degli operatori; infine, altri dati possono derivare dalla trasformazione di altri dataset acquisiti, attraverso la combinazione con altre variabili.
Il PLC
Abbiamo detto che lo scopo è quello di avere dei dataset organizzati. Questi dataset possono essere associati alle risorse gestite dal sistema (macchine, linee di produzione, ecc..): nel configurare i nostri dataset, saremo quindi chiamati a definire la struttura delle risorse, sino ad identificare la linea di produzione ed, infine i device IoT di campo, come ad esempio un PLC.
Facciamo l’esempio del PLC, perché già adottato nelle puntate precedenti.
Possiamo dialogare col PLC utilizzando diversi protocolli: Siemens, Modbus TCP, OPCUA.
Il PLC quindi sarà la nostra sorgente dati: attraverso un’interfaccia molto semplice è possibile rappresentare il PLC e i dataset associati e, infine, sarà possibile configurare le variabili di campo che ci servono, la frequenza di campionamento, l’indirizzo delle aree di memoria del PLC e altri parametri utili.
Questa è la nostra sorgente: estrarre i dati dal PLC è il lavoro che viene assegnato agli Agenti software di IMPROVE… vediamo di cosa si tratta.
IMPROVE 4.0
Agenti in missione
IMPROVE 4.0 è il framework di NeXT realizzato utilizzando un paradigma di programmazione molto innovativo: quello ad Agenti, particolarmente adatto per sviluppare algoritmi di Intelligenza Artificiale.
Detto in parole poverissime diremo che un Agente è un software che “vive” per perseguire una determinata missione.
In questo sistema di Data Acquisition gli agenti coinvolti sono diversi.
Un primo Agente ha la missione di prelevare, con una determinata frequenza, i valori delle variabili che risiedono in precise aree di memoria del PLC. Questi valori quindi vengono resi disponibili all’interno della memoria del sistema IMPROVE.
Queste informazioni vengono poi consegnate ad un altro Agente che ha la missione di “fotografare” il valore corrente delle variabili: questo agente di fatto costituisce la reale memoria di tutte le informazioni che fluiscono dal campo.
Infine questo agente, verrà “interrogato” da un terzo tipo di agente, il quale metterà i valori delle variabili in relazione con quelli che erano stati impostati in precedenza, in fase di configurazione.
Configurazione delle variabili
Facciamo un passo indietro, a quando abbiamo configurato le variabili del processo che ci interessa acquisire e monitorare.
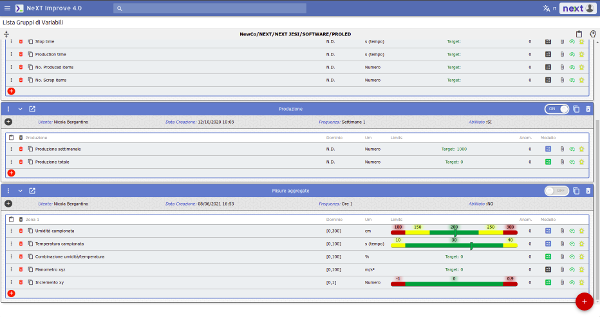
Configurazione delle variabili
Della variabile viene fornita una descrizione, definito un dominio, unità di misura, valori di riferimento o soglie di tolleranza. Al momento dell’acquisizione il terzo agente confronterà i valori in suo possesso con quelli configurati, andando a determinare la sussistenza o meno di un “fuori controllo”.
Il concetto di fuori controllo è assolutamente rilevante.
È alla base dell’automatizzazione della soluzione di Digital acquisition.
Il fuori controllo diventa subito un trigger per una serie di possibili azioni/eventi:
- Un feedback direttamente verso il processo
- L’invio di una e-mail
- La schedulazione automatica di un intervento di manutenzione CBM
- Invio di un messaggio su telegram
- Qualsiasi cosa possa servire
Il valore delle variabili configurate può essere di diverso tipo. Ad esempio può essere rappresentato da un limite, oltre il quale si ha un OOC (Out Of Control); può consistere in una soglia o intervallo. In questo caso verranno individuate delle zone, rappresentate da una diversa colorazione: il colore rosso rappresenta l’area di OOC; il verde e il giallo. Aree con valori accettabili.
Altri valori saranno il risultato del collegamento con altri dataset acquisiti attraverso la specificazione di un criterio di aggregazione, oppure di combinazioni con altre variabili attraverso modelli matematici.
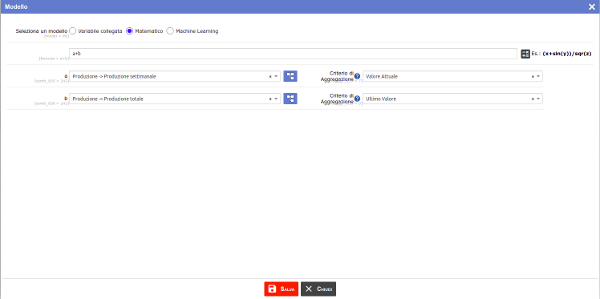
Modelli
Infine, è possibile importare modelli di deep learning e riuscire così a svolgere funzioni che sarebbero troppo complesse per un semplice modello matematico.
Data analysis
Una volta acquisiti tutti i dati è necessario passare alla fase di data analysis.
Per questo motivo i dati vengono strutturati e organizzati, sia in forme tabellari che grafiche.
Le tecniche utilizzate per la fase di analisi derivano direttamente dal controllo statistico di processo:
- Analisi dei trend della variabile
- Analisi statistica
- Analisi della capacità di processo (cp, cpk)
- Istogramma (forma della distribuzione)
- Analisi gaussiana
- Diagramma di Pareto
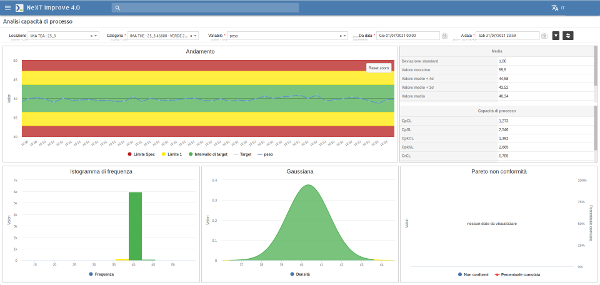
Data analysis & reports
CASSETTA DEGLI ATTREZZI:
– Un PLC
– Modulo Data acquisition
Se vi interessano i temi che affrontiamo, iscrivetevi alla nostra Newsletter, per rimanere sempre aggiornati sui contenuti che pubblichiamo.
Ci piacerebbe conoscere il vostro parere. Seguiteci su Linkedin!
Ma se volete seguirci nella maniera più veloce e agile, seguite il nostro canale su Telegram!
Ascoltando: U2 – “Beautiful day”
Lettura in corso: “Strategia oceano blu: vincere senza competere” di W. Chan Kim e Renée Mauborgne
Mood: Green















Commenti recenti